多文字を使う
はじめに
その名が表すとおり、「超漢字」の大きな特長は、多くの漢字や文字が使えることです。本稿では、超漢字の多文字環境を説明し、次に多文字環境を取り巻くソフトウェアを紹介します。
データの基本は文字
いまやコンピュータは、社会や生活のいろいろな場面で使われています。コミュニケーション手段としてメールは広く普及しましたし、インターネットやワープロはビジネスに欠かせません。顧客名簿から住民票まで、大量のデータがコンピュータ上で整理・活用されています。
このようなデータは、文章、人名といった「文字」から成り立っています。しかし、コンピュータで満足に文字を使えない場合がしばしばあります。
日本語は何文字ある?
日本語は、ひらがな、カタカナ、漢字など、数種類の文字を使って書かれます。手紙やビジネス文書の中には、数字やアルファベットも現れます。平均的に必要とされる文字の数は、数千字程度と言われています。しかし、生活の中で使われる文字の数は、人それぞれで大きく変わります。
たとえば「やかた」という言葉には、「館」と「舘」の2つの漢字があります。「舘」は義務教育課程で習う漢字ではありませんが、特に人名や地名、屋号などで、「館」と区別して使われています。「古舘」さんへ手紙を書くときに、「古館」と書くことはないでしょう。また珍しいと言われる文字でも、その字が住んでいる土地や名前に含まれている人にとっては、日常的によく使う文字です。
このように必要な文字を集大成していくと、日本語で使う文字はばく大になります。世界最大の漢字字典「大漢和辞典」には、5万字以上が掲載されています。
ところが多くのコンピュータは、扱える文字が7,000字程度しかありません。これでは文芸作品はもとより、日本人の名字を網羅することもできません。
コンピュータと文字
さて、コンピュータの内部では、文字はどのように扱われているのでしょうか。
コンピュータは、文字の形そのものではなく、文字に割り当てた「番号」を使って、文章を表現しています。例えば「私」という文字を「2768番」、「は」を「474番」と定め、「私は」という文章を「2768、474」と番号に交換して扱っています。コンピュータの内部には、文字の形と番号の対応表が用意してあります。文字を画面に表示したり印刷するときに、対応表を使って、番号を文字の絵に変換し直しています。
多くのコンピュータで7,000字程度の文字しか扱えないのは、この対応表が7,000字程しか用意されていないからです。
対して超漢字では、1枚で約65,000文字を収録できる対応表を、何枚でも持つことができます。内部的に対応表を切り替えることで、無限の文字を利用できるのです。
超漢字で利用できる文字
超漢字Vで利用できる文字は、全部で186,526字あります。
先ほど名前をあげた世界最大の漢字字典「大漢和辞典」をまるごと搭載しているほか、GT書体フォントによって、旧字・新字も学術用途までカバーしています。
日本以外の文字では、中国、韓国、台湾といった多文字も搭載しています。別々の発展を遂げた漢字の、特徴的な字形も区別することができます(図1)。

図1:日本・中国・韓国の字形の違い
またアルファベット系文字に関して、Unicodeの文字を登録しています。ラテン系、国際発音記号をはじめ、以下の文字が利用できます(表1)。
| ギリシャ | ベンガル | カンナダ |
| キリル | グルムキー | マラヤーラム |
| アラビア | グジャラティ | タイ |
| ヘブライ | オリヤ | ラオス |
| アルメニア | タミール | チベット |
| デヴァナガリ | テルグ | グルジア |
注意:アラビア語やヘブライ語など書記方向が異なる言語は、文字単位での利用になります。また、インド系文字の一部の表示形は搭載していません。
おもしろいところでは、携帯電話のiモードに採用されている「iモード絵文字」や、生きている象形文字としてデザイン分野でも注目されている「トンパ文字」、陰陽師が使ったとされる「陰陽五行文字」など、ユニークな記号・文字も使うことができます。
どこでも使える
超漢字の多文字環境はOSがサポートしているものですから、搭載されているすべての文字は、ワープロから表計算まで、アプリケーションを問わずあらゆる場面で利用することができます。他OSとデータをやりとりする場合は、超漢字の対応表番号(TRONコード)や、図形に変換することができるようになっています。これにより、超漢字どうしはもちろん、多文字環境でないOSとのメール、ファイル交換なども可能です。
では次から、多文字を取り巻くソフトウェアを見ていきましょう。
文字検索
超漢字には「文字検索」という小物(ユーティリティ)が付属しています。
文字検索小物は、超漢字に搭載されているすべての文字と記号を、さまざまな方法で探し出すことができるソフトウェアです(図2)。
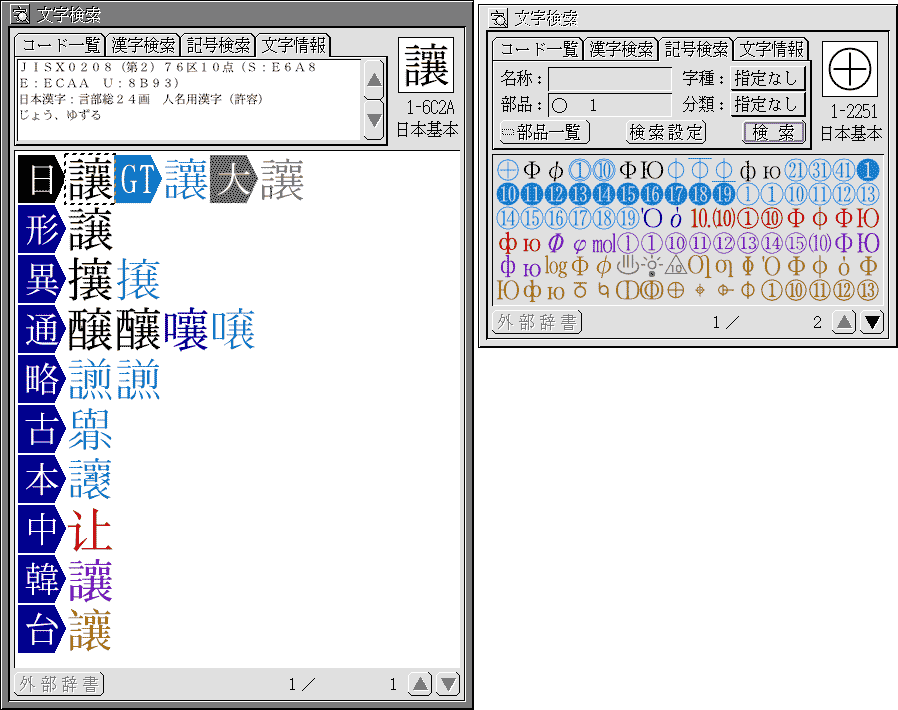
図2:文字検索小物
コード一覧から探す
探したい文字のコード番号がわかっているときは、〈コード一覧〉の画面を使うと便利です(図3)。
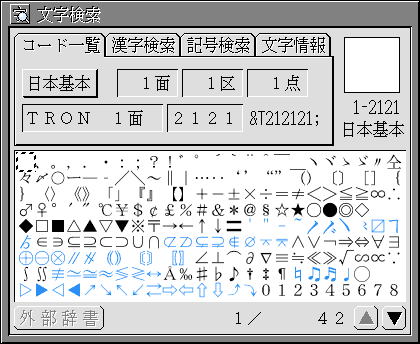
図3:文字検索〈コード一覧〉
コード番号を指定すると、右上に該当の文字が表示されます。コードは、JIS(日本)やGB(中国)などの面区点、Unicode(各国)・TRONなどの16進数のほかに、大漢和番号にも対応しています。大漢和番号は、学術資料や漢和辞典でよく使われているコード番号です。
漢字を探す
〈漢字検索〉の画面では、超漢字のすべての漢字を、よみ/画数/構成要素をキーにして探すことができます(図4)。
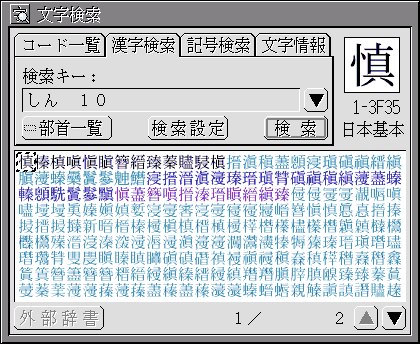
図4:文字検索〈漢字検索〉
よみはひらがなで、画数は「=」をつけた数字で指定します。図4は、「しん」というよみで10画の漢字を検索しています。「=10~15」といったように、キーに指定する画数の範囲を広げることもできます。キーを複数指定する場合は、スペースで間を区切ります。
漢字を構成要素から探すときは、探したい漢字の一部を指定します。
例えば「嶋」という字を探すときは、キーを「山 鳥」にすればよいのです。部首の指定とは違うため、紙の辞書の索引のように木部と鳥部のどちらにあるか迷う必要はありません。キーを「山」にしたときは、「幽」のように「山」の形を含むすべての漢字がヒットします。
構成要素は、すべて書かなくてもかまいません。「憂鬱」の「鬱」など複雑な文字でも、目立つ部分「木 缶 木」を指定するだけで絞り込むことができます。また同じ要素が複数あるときは、「×」や「*」を使ってひとまとめにできます。「鬱」の場合、「木×2 缶」でも探せます。
「亠」など、キーによく使われる部首は、[部首一覧]にまとめてあります。形の似たカタカナも、構成要素として使えます。「イ」を人偏の代りに使ったり、「シ エ」で「江」、「ツ ワ カ」で「労」を探すことができます。
マイナス指定は、漢字の一部を抜き出すときに使います。「登-豆」と書くことで、「癶」を指定したときと同じ結果が得られます。これはコンピュータならではの機能なので、ぜひ覚えてください。
キーにピリオド「.」を入れると、キーに完全一致する漢字だけが検索されます。「山 豆」とすると、「凱鎧剴嶝榿…」とたくさんの漢字が表示されますが、「山 豆 .」とピリオドを入れることで、その2つだけで構成される「豈」のみに絞り込むことができます。
指定が難しい構成要素は、要素の画数だけを指定することが可能です。指定には数字(「=」を入れない)を使います。「彝」を引くとき、「米糸」までは簡単ですが、「彑」や「廾」のマイナス指定やカタカナ指定はなかなか浮かびません。「米 糸 3」とすると、「米」「糸」の他に3画の構成部品 (彑廾下干丸…)を含んだ字を見つけられます。
さらにもうひとつ、指定した構成要素は、その異体も自動的に検索されます。つまり「木 寿」をキーにした場合、「梼」だけでなく、「寿」の異体である「壽」を含んだ「檮」も同時にヒットします。
キーの指定は、「ある漢字を人に電話で伝えるとき、何というか」をイメージするとよいでしょう。「謳」という字は、「総画数が18か19画の"うたう" (=18~19 うたう)」と伝えるかもしれませんし「言偏に品とあと2画(言 品 2)」と言うかもしれません。「区の旧字(區)」「トボソの右側(樞-木)」のような表現もできます。文字を説明するつもりでキーを指定すれば、目的の漢字は簡単に見つかるでしょう。
記号を探す
漢字と同じく、〈記号検索〉の画面でアルファベットや記号を探すことができます(図5)。
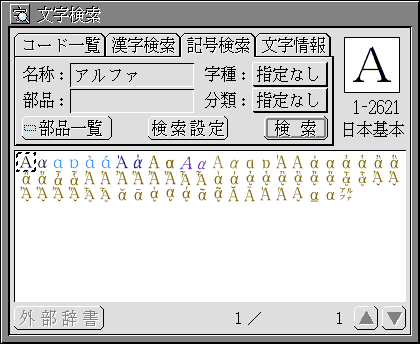
図5:文字検索〈記号検索〉
[名称]は、文字の名称(よみ)をキーにして検索するための場所です。「ハート」と入れれば白抜きのハートやハート付き感嘆符などを、「KA」と入れれば各国で「カ」と読む文字(かカКк…)を探し出すことができます。
[部品]には、探したい文字の構成要素や、感覚的に似た文字を入れます。
「C」を指定した場合、「℃」「¢」「cm」など「C」を含む文字のほかに、「C」に類似した「⊂」や「⊇」が見つかります。先ほどの「KA」を[部品]に書くと、「kA」(キロアンペア)の記号などがヒットします。
よく使われる要素を[部品一覧]から選ぶこともできます。
複数の構成要素をスペースで区切るのは漢字検索と同じですが、「=」「.」「×」といった特殊なキー指定は、記号検索にはありません。「=」なども、構成要素として検索されます。
[字種]は、地域や文字の成り立ちを元に、12項目から検索する文字の種類を絞り込むために使います。項目と字種の対応は、以下のとおりです(表2)。
| 指定なし | 《すべて》 |
|---|---|
| ラテン | 《ラテン》 |
| キリル | 《キリル | アルメニア | グルジア》 |
| ギリシア | 《ギリシア | コプト》 |
| アラビア | 《アラビア》 |
| ヘブライ | 《ヘブライ》 |
| インド | 《オリヤ | カンナダ | グジャラティ | タミル | テルグ | デバナガリ | ベンガル | マラヤーラム》 |
| タイ | 《タイ | ラオス》 |
| ハングル | 《ハングル | 韓国》 |
| 中国 | 《チベット | ボポモフォ | 杭州 | 中国 | 台湾 | トンパ》 |
| 日本 | 《仮名 | 平仮名 | 片仮名 | 日本》 |
| その他 | 《ローマ | 点字 | ホツマ | アーヴ》 |
[分類]は、絵文字やアルファベットなど、文字の属性で絞り込みをするために使います。項目と属性の対応は、以下のとおりです(表3)。
| 指定なし | 《すべて》 |
|---|---|
| 大小文字 | 《大文字・小文字の区別のあるアルファベット、国際音声字母(IPA)など》 |
| 文字一般 | 《大文字・小文字の区別のない文字。平仮名、片仮名、ハングル、アジア系の言語など》 |
| 数字 | 《数字と数字の含まれる記号》 |
| 記号一般 | 《句読点、かぎ括弧、算術記号、漢字など》 |
| 発音記号 | 《声調記号、修飾記号など》 |
| 図形 | 《絵文字、矢印、罫線など》 |
| 単位 | 《単位記号、通貨など》 |
それぞれのキーを組み合わせることで、効率よく文字や記号を探すことができます。例えば[字種]と[分類]の組み合わせで、インド系文字の数字を抜き出したり、大文字・小文字の区別のあるアルファベットで、「U(ウ)」とよむ字だけを見たりすることができます。
異体字や関連字から探す
[文字情報]の画面で、文字の関連性から特定の字を探すことができます。また漢字の画数やよみ、部首を確認したり、記号の名称を知ることもできます(図6)。
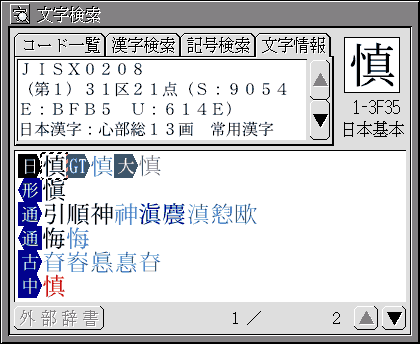
図6:文字検索〈文字情報〉
〈コード一覧〉〈漢字検索〉〈記号検索〉で文字を選び、〈文字情報〉の画面に移動すると、その文字の各種情報が表示されます。他ウィンドウから〈文字情報〉の画面に文字をドラッグ&ドロップして、情報を確認することもできます。
画面下半分には先頭の文字に対する関連字が示されます。関連字の分類は、以下のとおりです(表4)。
| 大文字 | アルファベットの大文字と小文字の関係における、大文字。 |
|---|---|
| 小文字 | アルファベットの小文字と大文字の関係における、小文字。 |
| 異形字 | 特定のパターンで変形した漢字の関係(新旧字など)。またインド系文字の字形変化や、意味が同じ記号類の関係。 |
| 関連字 | 意味や字体が広く関連する文字・記号類の関係。 |
| 異体字 | 意味や字体、発音などが関連する漢字の関係。また、形が似ている記号類の関係。 |
| 略字 | 点画を省いて簡略にした字体と、その元になったとされる漢字。 |
| 通用字 | 意味や読み上で交換が行われる漢字の関係。また、日常的に使われている漢字や誤って定着した字体とその元になったとされる漢字。 |
| 古字 | 魯の恭王が孔子の旧宅を壊したときに出てきたとされる字体と、そこから派生した漢字。 |
| 本字 | 漢和辞典で親字として掲載される字体と、現在一般的に使われている字体。 |
| 篆字 | てんじ。前三世紀ごろに中国で使われていた字体と、そこから派生した漢字。 |
| 籀字 | ちゅうじ。周王朝の史官が作ったとされる字体と、そこから派生した漢字。 |
| 隷字 | れいじ。篆字を省略した字体と、その元になったとされる漢字。 |
| 日本漢字 | 中国・韓国・台湾の漢字に対する日本の漢字。 |
| 中国漢字 | 日本・韓国・台湾の漢字に対する中国の漢字(簡体字)。 |
| 韓国漢字 | 日本・中国・台湾の漢字に対する韓国の漢字。 |
| 台湾漢字 | 日本・中国・韓国の漢字に対する台湾の漢字(伝統字)。 |
これにより、例えば新字から旧字の漢字を簡単に見つけることができます。「慎」という字の文字情報を見ると、旧字にあたる「愼」が現れます。異体字などの関係を知っているときは、漢字検索や記号検索で検索するよりも、目的の字を早く探し出すできます。
多文字を入力する
文字検索で探した文字は、ドラッグ&ドロップやトレーを使って別のウィンドウに持っていくことができます。
また、超漢字のかな漢字変換は、あらゆる文字をユーザ辞書に登録できるようになっています。頻繁に使う文字や単語は、ユーザ辞書に登録しておくと便利でしょう(図7)。
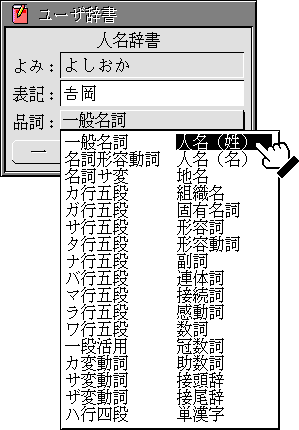
図7:ユーザ辞書小物
世界文字入力
キーボードから多文字を直接入力する方法として、「世界文字入力」がシステムに組み込まれています(図8)。

図8:世界文字入力
世界文字入力を使えば、各言語をネイティブ配列で入力したり、アルファベットの符号修飾を[変換]キーや[無変換]キーで行えるようになります。
言語モジュールを「世界文字入力」小物のウィンドウにドラッグ&ドロップすれば、言語の入力体系が追加されます。超漢字には、以下の31種類の言語モジュールが付録されています(表5)。不要な言語モジュールの削除も世界文字入力のウィンドウで行います。入力言語の切り替えは、キーボードでも操作できます。
| 中国語(簡体字) | イタリア語A | チェコ語 |
| 中国語(伝統字) | イタリア語B | スロベニア語 |
| 韓国語 | ロシア語A | トルコ語 |
| アイヌ語 | ロシア語B | ギリシア語 |
| 欧州文字 | アイスランド語 | ベトナム語 |
| フランス語A | デンマーク語 | ピンイン |
| フランス語B | ノルウェー語 | インド系言語ローマナイズ |
| ドイツ語A | スウェーデン語 | エスぺラント語A |
| ドイツ語B | フィンランド語 | エスぺラント語B |
| スペイン語A | ハンガリー語 | |
| スペイン語B | ポーランド語 |
注意:モジュール名の後ろの「A」は106 QWERTYカスタム配列、「B」はネイティブ配列です。
言語モジュールは、専用のプログラミング言語で書かれたもので、ユーザーによるカスタマイズや新規作成が可能です。専門語を追加したり、入力時にスペルチェックを行うモジュールを作ることもできます。
実身仮身検索
多漢字を含む文章を効率的に検索するため、超漢字には、「実身仮身検索」が装備されています。
実身仮身検索は、実身(ファイル)名やその中身を検索するOSの機能です。「異形字ゆらぎ検索」により、各国の大文字・小文字だけでなく、記号や、細かい漢字の字形差、新旧漢字、日本・中国・韓国・台湾の漢字を、区別なく検索することができます(図9)。
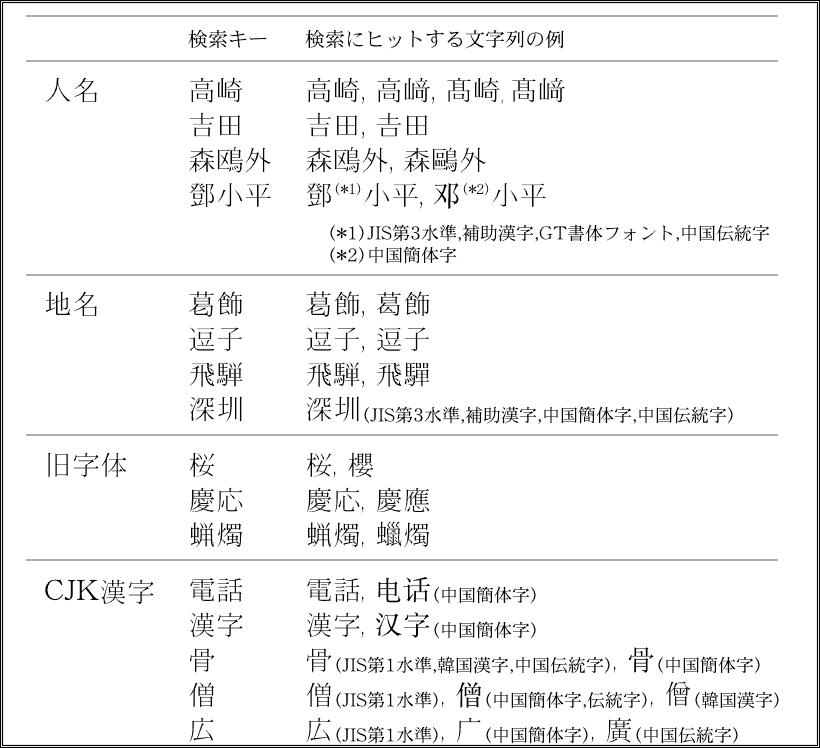
図9:検索できる文字列の例
HOME > 製品紹介 > 多漢字、多文字機能を実現 > 多文字を使う